

AI 전문기업으로 자리매김 ‘엔비디아’ vs FPGA 기술 손에 넣은 ‘인텔’ vs FPGA 최강자 ‘자일링스’
[테크월드=이나리 기자] 클라우드 컴퓨팅, 빅데이터, 인공지능에 대한 관심이 증대되면서 반도체 칩은 자체 인공지능 시스템 구현을 위해 꼭 필요한 요소가 되고 있다. 이처럼 차세대 먹거리로 주목 받고 있는 인공지능 시장에서 선두를 차지하기 위한 반도체 기업간 경쟁은 더욱 거세지고 있다. 최근 반도체 업체들의 인공지능을 타겟으로 한 반도체 칩 출시는 그 어느 때 보다 활발하다.
GPU의 강세에 힘입어 인공지능 전문 기업이라는 이미지 메이킹에 성공한 엔비디아는 신제품을 지속적으로 출시하고 있으며, 여러 산업 분야 기업들과 기술 협력을 가장 활발하게 전개하고 있다.

◇ 엔비디아, GPU로 인공지능 기술협력 활발
엔비디아의 가장 최근 기술인 GPU 컴퓨팅 아키텍처인 볼타(Volta)와 볼타 기반의 최초의 프로세서인 엔비디아 테슬라(NVIDIA Tesla) V100 데이터센터 GPU는 지난 5월 개최된 엔비디아의 GPU 테크놀로지 컨퍼런스(GPU Technology Conference, 이하 GTC)에서 첫 공개됐다.
엔비디아의 7세대 GPU 아키텍처인 볼타는 210억개 트랜지스터로 구축됐으며, CPU 100대와 같은 수준의 성능으로 딥러닝을 구현한다. 볼타의 테라플롭 피크 성능은 엔비디아의 현 세대 GPU 아키텍처인 파스칼(Pascal) 대비 5배, 2년 전 출시된 맥스웰(Maxwell) 아키텍처 대비 15배 향상됐다는 것이 엔비디아 측의 설명이다. 또 쿠다(CUDA) 코어와 새로운 볼타 텐서 코어(Volta Tensor Core)를 통합 아키텍처에 결합시킴으로써, 테슬라 V100 GPU를 탑재한 1대의 서버는 기존 고성능 컴퓨팅에 필요한 수백 개의 일반 CPU를 대체할 수 있다고 한다.
앞서 엔비디아는 2016년 GPU 테크놀로지 컨퍼런스에서 16나노 제조공정으로 생산된 GPU `파스칼`과 이 파스칼을 탑재한 `테슬라 P100`를 선보였는데, 이 제품은 지난 1년동안 여러 산업에 접목시킨 성과를 얻었다. 파스칼은 153억개의 트랜지스터가 집적됐고, 28나노 공정으로 생산된 종전 맥스웰(약 90억개) 대비 트랜지스터 숫자가 60억개나 늘어난 제품이다. 또 대역폭을 넓혀 데이터 처리 속도를 높인 고대역폭메모리2(HBM2)를 탑재하고, GPU와 CPU가 직접 통신하는 NV링크 기술을 적용해 전체 성능을 향상시켜 인공지능 기술을 한차원 끌어올렸다고 평가 받고 있다.

엔비디아의 최근 성과를 살펴보면, 올해 파스칼 GPU 기반 테슬라는 마이크로소프트 애저 클라우드 내 새로운 인스턴스에 적용됐고, 인공지능 기능 강화를 위해 바이두 클라우드와 IBM의 클라우드에 적용시켰다. IBM 클라우드의 경우에는 엔비디아 테슬라 P100 데이터센터 GPU 두 대를 장착시킴으로써 개별 IBM 블루믹스 베어메탈(Bluemix bare metal) 서버를 구축할 수 있게 됐다. 또 GPU 가속 클라우드 인스턴스의 경우 최대 비가속 서버 25대의 성능을 구현할 수 있어 HPC와 AI 워크로드 관련 비용 절감 효과를 얻게 됐다.
또 8개의 엔비디아 테슬라 P100은 올해 페이스북(Facebook)의 차세대 AI 서버 ‘빅 바신(Big Basin)’에 탑재되면서 페이스북 내 게재된 이미지의 사물 또는 사람의 얼굴을 인식하거나, 실시간 텍스트 번역, 사진, 동영상 콘텐츠의 내용을 보다 정확히 이해할 수 있도록 지원하고 있다. 국내에서는 한화테크윈이 개발하는 인공지능 기반 보안 솔루션에 테슬라 P100이 적용됐다.
엔비디아의 GPU는 자율주행차, 가상현실 등 미래 첨단 기술 분야를 비롯해 교통, 금융, 정부/국방, 헬스케어 분야 등 다양한 산업 분야의 인공지능 시스템을 지원하고 있다. 특히 2016년 엔비디아는 자율주행차 부문에서 세계 최초의 인공지능 기반 슈퍼컴퓨터인 '드라이브 PX 2'를 공식 발표한 바 있다.
자동차 주행 시에는 주변 사물 인식이 특히 중요한데, 엔비디아 드라이브 PX 2는 두 개의 엔비디아 차세대 테그라(Tegra) 프로세서와 별도의 파스칼(Pascal) 아키텍처 기반 GPU 두 개를 탑재해 차량 주변 상황을 360도 전방위적으로 인식하고 대량의 데이터를 신속하게 처리한다. 이는 차량의 글러브박스에 들어갈 만한 작은 사이즈의 이 슈퍼컴퓨터가 제공하는 1초에 최대 24조 회의 작업을 처리하는 프로세스 성능에 기반해 구현된다.
이와 관련해 엔비디아는 자동차부품 제조업체인 보쉬(Bosch)와의 양산용 자동차를 위한 인공지능 자율주행 시스템 개발 협력을 지난 3월 발표했다. 본 인공지능 차량용 컴퓨터 시스템의 기반이 되는 자비에(Xavier)에는 엔비디아 드라이브 PX가 탑재돼 레벨 4 수준의 자율주행 구현을 위해 설계된 세계 최초의 단일칩 프로세서다. 자비에는 자율주행 차량이 필수적으로 수행해야 하는 작업, 주변 환경의 감지를 위한 딥 뉴럴 네트워크 적용, 3D 환경 파악, HD맵 상에서 차량 스스로의 위치 파악, 주변 사물의 행동과 위치 예측, 그리고 차량 동역학과 안전 주행 경로의 연산 등을 구현한다.

◇ 인텔, CPU에 알테라 FPGA 기술 접목
그동안 인텔은 인공지능 포트폴리오에 ASIC나 FPGA 제작 보다는 자사의 CPU 프로세서를 더욱 강력하게 만드는 전략을 취해왔다. 그러나 인텔은 인공지능 특화 기술을 확보하기 위한 전략으로 2015년 FPGA를 제조하는 알테라(Altera)를 167억 달러에 인수했고, 2016년 8월에는 소프트웨어에서부터 칩에 이르기까지 특수 인공지능 시스템을 개발하는 너바나(Nervana)를 4억 달러에 인수했다.
같은 해 인텔은 인공지능 시스템 공급 업체인 사프론(Saffron)을 인수하면서 소형기기에서, IoT, 제조, 금융, 리테일 등의 여러 분야에 인공지능을 접목시키겠다는 의지를 내비쳤다. 인텔의 이 같은 행보는 엔비디아와 경쟁구도에서 뒤쳐지지 않으려는 움직임으로 보여진다.
인텔은 차후 기계학습과 심층학습용 제품 브랜드를 ‘인텔 너바나’로 정하고, 다양한 마케팅 활동과 제품 출시를 전개하고 있다. 그 1탄이 2016년 하반기 개최된 인텔 AI 데이즈에서 2017년 전반기 투입이 계획된 머신러닝용 칩 ‘레이크 크레스트(개발코드네임)’다. 레이크 크레스트는 한마디로 표현하자면, 심층학습용 학습 액샐러레이터다.
텐서(Tensor) 기반 아키텍처를 채용하고 있으며, 내장된 12개의 프로세서 클러스터(1개 클러스터당 코어 수 등은 미공개)를 이용해, 기존 GPU 대비 10배의 효율로 병렬 연산을 할 수 있고, 텐서 오퍼레이션당 전력효율은 GPU보다 우수하다는 것이 인텔 측의 설명이다.
메모리 대역에서 병목이 생기지 않도록, 메모리는 HBM2를 32GB 탑재하고 있으며, 대역폭은 8Tbps에 달한다. 복수의 칩을 접속한 경우에는 인텔 독자의 ICL(Inter-Chip Link)을 이용해, PCI Express를 이용한 경우에 비해 20배 빠른 속도로 데이터를 처리할 수 있다. 인텔에 따르면 너바나에는 삼성전자가 생산하는 3D 고대역폭 메모리(HBM)가 사용될 예정이다.

인텔은 추가로 심층학습에 최적화된 제온 파이인 ‘나이츠 밀(Knights Mill)’을 올해 3분기 중에 출시할 예정이다. 또 제온과 레이크 크레스트처럼 액샐러레이터를 탑재한 ‘나이츠 크레스트(Knights Crest)’라는 칩도 개발 중에 있다.
인텔은 FPGA도 적극적인 개발에 돌입했다. 인텔의 ‘아리아(ARRIA) 10 FPGA’는 데이터를 수집하고 전송하는 한편, 다양한 IoT기기에서 수집된 정보를 기반으로 실시간 결정을 내릴 수 있도록 지원한다. 설계자들은 FPGA를 활용해 다양한 IoT 애플리케이션이 필요로 하는 특정수준의 컴퓨팅 성능을 구현하고, 프로그래밍할 수도 있다. 지난 2월 인텔은 산업용 IoT와 자동차 시장을 겨냥한 FPGA ‘사이클론 10 시리즈’ 10GX와 10LP를 선보인바 있다. 업계에서는 향후 어느 시점에서는 인텔의 CPU가 알테라의 FPGA와 결합될 것으로 예상되고 있다.
인텔은 제온 파이와 제온 프로세서를 통해 인공지능 개발을 가속화한다는 전략이다. 제온 파이는 부팅이 가능한 호스트 프로세서로서 유연성을 갖춰 다수의 분석 워크로드를 처리할 수 있다. 특히 인텔 제온 프로세서 ‘E7 v4’ 제품군은 IBM ‘파워 8(Power 8)’ 기반 솔루션과 비교해 절반의 전력으로 최대 1.4 배 높은 성능과 최대 10배의 달러 당 성능을 제공한다는 것이 인텔 측의 설명이다.

◇ 자일링스, 강력한 FPGA 기술로 속도 차별화
FPGA 전문 반도체 기업인 자일링스도 2016년 11월 하이퍼스케일 규모의 데이터센터를 겨냥한 기술을 발표했다. 하이퍼스케일 데이터센터는 전체 서버 시장에서 차지하는 비중은 낮지만 구글, 마이크로소프트, 아마존 등 대형 인터넷 서비스 업체들이 대량으로 도입하면서 최근 급성장하고 있다.
일례로, 2016년 10월 바이두는 머신러닝 애플리케이션 가속을 위해 자일링스 울트라스케일 FPGA를 사용하고 있다고 발표했고, 같은 해 11월에는 아마존이 새로운 F1 인스턴스 서비스를 출시하면서 자일링스 제품을 활용하겠다고 발표했다. 퀄컴과 IBM도 데이터센터 가속을 위해 자일링스와 전략적으로 협력한다고 발표했다.
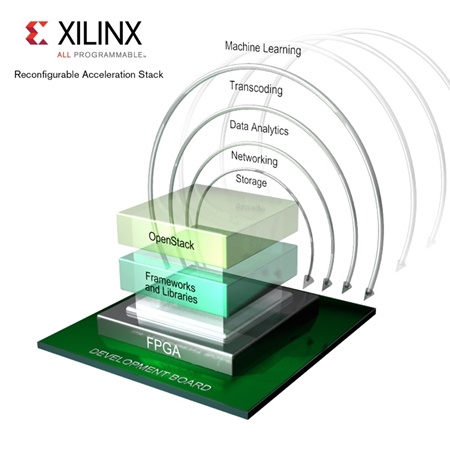
클라우드 애플리케이션을 위해 설계된 자일링스의 FPGA로 구동되는 가속 스택(Reconfigurable Acceleration Stack) ‘reVISION’은 개발자보드와 FPGA, 프레임워크, 라이브러리, 오픈스택 등이 포함돼 있는 것이 특징이다. 자일링스는 “reVISION은 경쟁사의 임베디드 GPU와 일반적인 SoC에 비해 머신 러닝 추론에서 최대 6배 더 뛰어난 이미지/초/와트, 컴퓨터 비전 처리에서 40배 더 뛰어난 프레임/초/와트, 1/5의 레이턴시가 특징”이라고 설명했다.
◇ IBM, 프로세서 구조를 개방형 소프트웨어로 개발
IBM 역시 2013년에 ‘파워(Power)’라 불리는 자사 프로세서 구조를 개방형 소프트웨어 방식으로 개발했고, 이를 통해 특수 칩 제조업체들은 IBM의 파워 CPU와 자사 칩을 쉽게 연동시킬 수 있게 됐다. IBM은 파워 프로세서 개발을 지속하고 있으며, 2016년 선보인 엔비디아 NV링크(NVLink) 지원 ‘파워 8+(POWER 8 with NVLink)’ 프로세서에 이어 올해 하반기에는 NV링크 2.0 버전을 지원하는 ‘파워9’의 출시를 계획하고 있다.
IBM 측에 따르면 ‘파워9’은 14나노의 핀펫 공정으로 생산되며, 24코어에 코어 당 4스레드와 8스레드 두 가지 구성으로 준비 중이다. 파워9은 엔비디아의 GPU를 이용하는 헤테로지니어스 컴퓨팅 환경을 구성할 경우, PCIe 3.0 기반 GPU 연결 시스템과 비교 시 7배에서 10배에 달하는 성능을 향상할 것으로 예상된다고 밝혔다.
인공지능은 자율주행차, 스마트홈, 스마트시티, 의료, 금융, 서비스업, 교육 등 전 산업에서 새로운 핵심 기술로 부상하며 성장 가능성이 무궁무진하다. 반도체 업계에서는 인공지능에 대한 관심과 수요를 충족시키기 위해 딥러닝 교육 프로그램을 개최하고 전문가 양성, 기술 저변 확대에도 적극적으로 나서고 있다. 인공지능 시장의 선두를 차지하기 위한 기술 경쟁은 앞으로 더욱 심화될 것으로 보여진다.
※ 관련 기사
인공지능 칩 강자는 누구? GPU vs FPGA vs ASIC (3)
그래도 삭제하시겠습니까?